Hadoop之MapReduce介绍整理 什么是批处理 在了解MapReduce之前,需要了解批处理的概念,批处理模式是一种最早进行大规模数据处理的模式。批处理主要操作大规模静态数据集,并在整体数据处理完毕后返回结果。...
”hadoop 算法 mapreduce“ 的搜索结果

该项目实现了KNN算法在Hadoop平台基于欧拉距离,加权欧拉距离,高斯函数的MapReduce实现。 特色或创意:实例上添加了基于欧拉距离,加权欧拉距离,高斯函数的实现。 使用的是著名的鸢尾花数据集。据集内包含 3 类...

Hadoop-Mapreduce 1. 扑克牌问题 假如你有2000副四大名著主题扑克牌。现在将他们全部混合在一起,然后从中随机抽出一部分丢 掉,现在要求你统计出每种名著分别有多少张? 统计扑克牌人数不限(20人) 2. ...
Spark框架包含多个紧密集成的组件,包括Spark SQL(即席查询)、Spark ...4、随处运行:用户可以使用Spark的独立集群模式运行Spark,也可以在亚马逊弹性计算云、Hadoop YARN资源管理器或Apache Mesos上运行Spark。
什么是Hive:专门对大数据进行离线的分析使用的工具适用于数据分析,特征处理等任务,它的底层是把HQL转化为MapReduce程序,并且数据存储在HDFS上,程序运行在yarn上。(经常是深夜的定时任务,处理完后自动存放入...
基于Apriori算法的频繁项集Hadoop mapreduce.rar
Hadoop-MapReduce下的PageRank矩阵分块算法 高清完整中文版PDF下载
# 基于Hadoop下MapReduce框架的并行C4.5算法 > 项目来源于**西南交通大学**信息科学与技术学院**计算科学与技术专业**毕业设计 ## 说明 * 程序利用Eclipse EE在Hadoop平台下,使用Map/Reduce编程框架,将传统的C...
Spark 生态圈是加州大学伯克利分校的 AMP 实验室打造的,是一个力图在算法、机器、人之间通过大规模集成来展现大数据应用的平台。AMP 实验室运用大数据、云计算、通信等各种资源及各种灵活的技术方案,对海量不透明...
1)什么是序列化序列化就是把内存中的对象,转换成字节序列(或其他数据传输协议)以便于存储到磁盘(持久化)和网络传输。反序列化就是将收到字节序列(或其他数据传输协议)或者是磁盘的持久化数据,转换成内存中...
人工智能-Hadoop
人工智能-hadoop
使用Hadoop Mapreduce 实现酒店评价文本情感分析 使用的算法为朴素贝叶斯高斯模型 qingganenxi.py文件为预测程序 其它文件为Java程序,用于训练模型
MapReduce是hadoop的核心组件之一,hadoop要分布式包括两部分,一是分布式文件系统hdfs,一是分布式计算框,就是mapreduce,二者缺一不可,也就是说,可以通过mapreduce很容易在hadoop平台上进行分布式的计算编程...
目录 一、 MapReduce概述 1.1 MapReduce定义 ...二、 Hadoop序列化 2.1 序列化概述 2.2 自定义bean对象实现序列化接口(Writable) 三、 MapReduce框架原理 3.1 InputFormat数据输入 3.1.1 切片与MapTas
小编也是很有感触,如果一直都是在中小公司,没有接触过大型的互联网架构设计的话,只靠自己看书去提升可能一辈子都很难达到高级架构师的技术和认知高度。向厉害的人去学习是最有效减少时间摸索、精力浪费的方式。...
第1章 MapReduce概述 1.1 MapReduce定义 1.2 MapReduce优缺点 1.2.1 优点 1.2.2 缺点 MapReduce核心思想 MapReduce核心编程思想,如下图 1)分布式的运算程序往往需要分成至少2个阶段。 2)第一个阶段的Map...
接下来,我们将深入探讨大数据处理的核心技术,包括Hadoop与MapReduce。 # 2. Hadoop概述 Hadoop是一个开源的分布式计算框架,旨在解决处理大规模数据的问题。它能够将大规模数据集分布在多台计算机集群上进行处理...
学完之后,若是想验收效果如何,其实最好的方法就是可自己去总结一下。比如我就会在学习完一个东西之后自己去手绘一份xmind文件的知识梳理大纲脑图,这样也可方便后续的复习,且都是自己的理解,相信随便瞟几眼就能...
hadoop之MapReduce的一些简介,架构和分析
一、Hadoop简介 Hadoop最早只是单纯的值分布式计算系统,但随着时代的发展,目前hadoop已成了一个完整的技术家族。从底层的分布式文件系统(HDFS)到顶层的数据解析运行工具(Hive, Pig),再到分布式协调服务...
Hadoop_MapReduce 使用Hadoop进行大数据处理 该项目在Hadoop框架上使用Map-Reduce从零开始实现基本的文本处理任务,例如字数,n元语法,倒排索引,关系连接和k近邻算法。

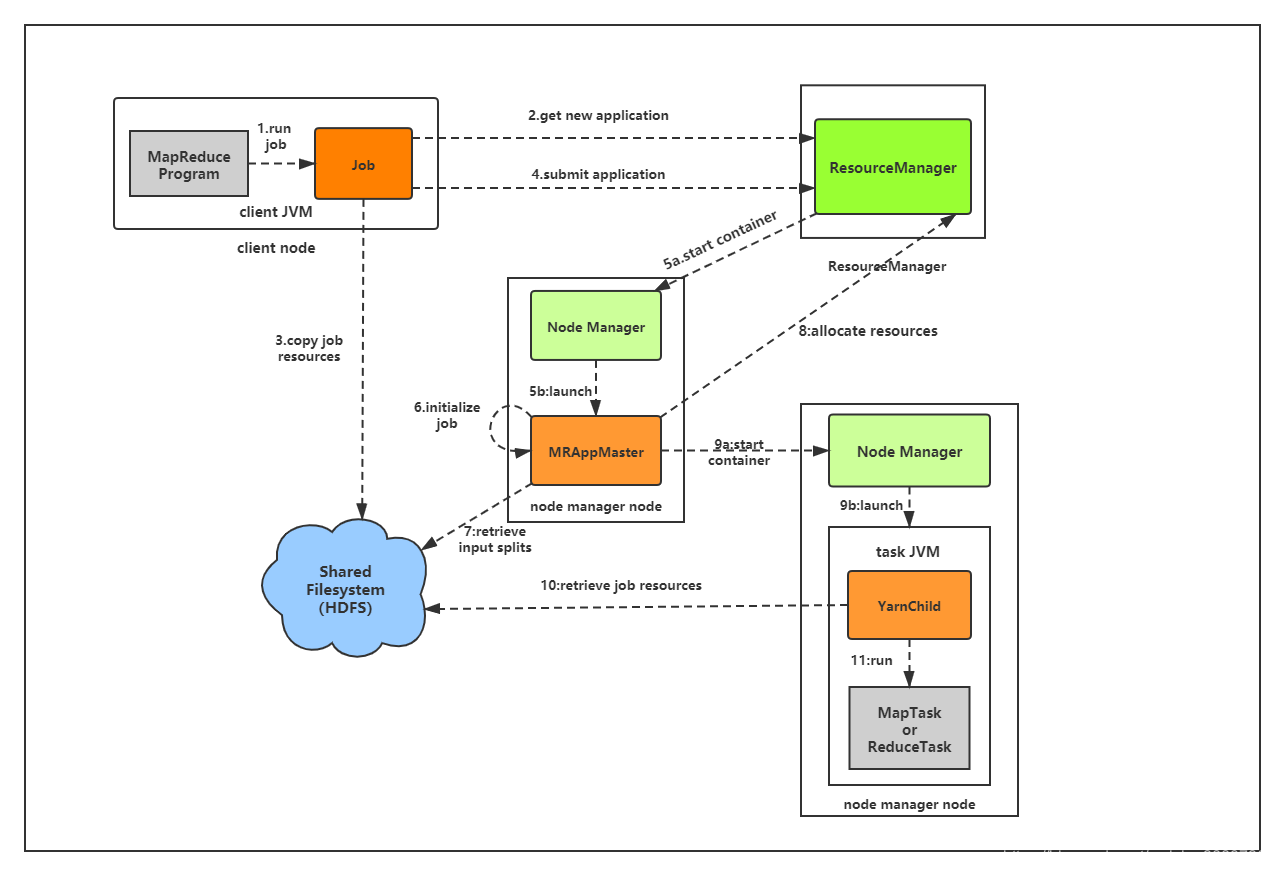
一、MapReduce数据处理流程 关于上图,可以做出以下逐步分析: 输入数据(待处理)首先会被切割分片,每一个分片都会复制多份到HDFS中。上图默认的是分片已经存在于HDFS中。 Hadoop会在存储有输入数据分片(HDFS中...
如果使用某一个字段进行辅助排序,那么这个字段"必须"在之前"有过排序"的处理,所有"辅助"顾名思义就是在前者排序好的基础上发挥的作用, 单独使用的辅助排序 很可能生成的结果顺序是乱的,最好不要使用。...
hadoop基于MapReduce实现TFIDF算法完成热点词汇抓取首先了解TFIDF环境步骤开始 首先了解TFIDF TF-IDF的主要思想是,如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有...
通过充分利用分布式计算,Hadoop实现了对大规模数据的高效处理,使得复杂的数据分析任务变得...通过这一实践案例,我们可以深入了解Hadoop的MapReduce编程模型,以及如何在实际应用中利用其优势来处理和分析海量数据。
推荐文章
- 大数据和云计算哪个更简单,易学,前景比较好?_大数据和云计算哪个好-程序员宅基地
- python操作剪贴板错误提示:pywintypes.error: (1418, 'GetClipboardData',线程没有打开的剪贴板)...-程序员宅基地
- IOS知识点大集合_ios /xmlib.framework/headers/xmmanager.h:66:32: ex-程序员宅基地
- Android Studio —— 界面切换_android studio 左右滑动切换页面-程序员宅基地
- 数据结构(3):java使用数组模拟堆栈-程序员宅基地
- Understand_6.5.1175::New Project Wizard_understand 6.5.1176-程序员宅基地
- 从零开始带你成为MySQL实战优化高手学习笔记(二) Innodb中Buffer Pool的相关知识_mysql_global_status_innodb_buffer_pool_reads-程序员宅基地
- 美化上传文件框(上传图片框)_文件上传框很丑-程序员宅基地
- js简单表格操作_"var str = '<table border=\"5px\"><tr><td>序号</td><-程序员宅基地
- Power BI销售数据分析_powerbi汇总销售人员业绩包括无销售记录的人-程序员宅基地